Tech and Product
How we wrote a pipeline abstraction module with one line of code

A declarative implementation of the pipeline design pattern for maintaining rapidly evolving and complex data science workflows.
Motivation:
At the core of all the products at Locus lie complex mathematical models and large workflows which are expected to perform at scale. None more so than our brand new strategic supply chain planning platform, Locus NodeIQ.
NodeIQ is fueled by an externalized mathematical modeler, written in Python, called Neo. It is responsible for converting a supply-chain optimization request to a mathematical model with millions of variables.
Below is a simplified representation of the workflow that drives network optimization at NodeIQ –
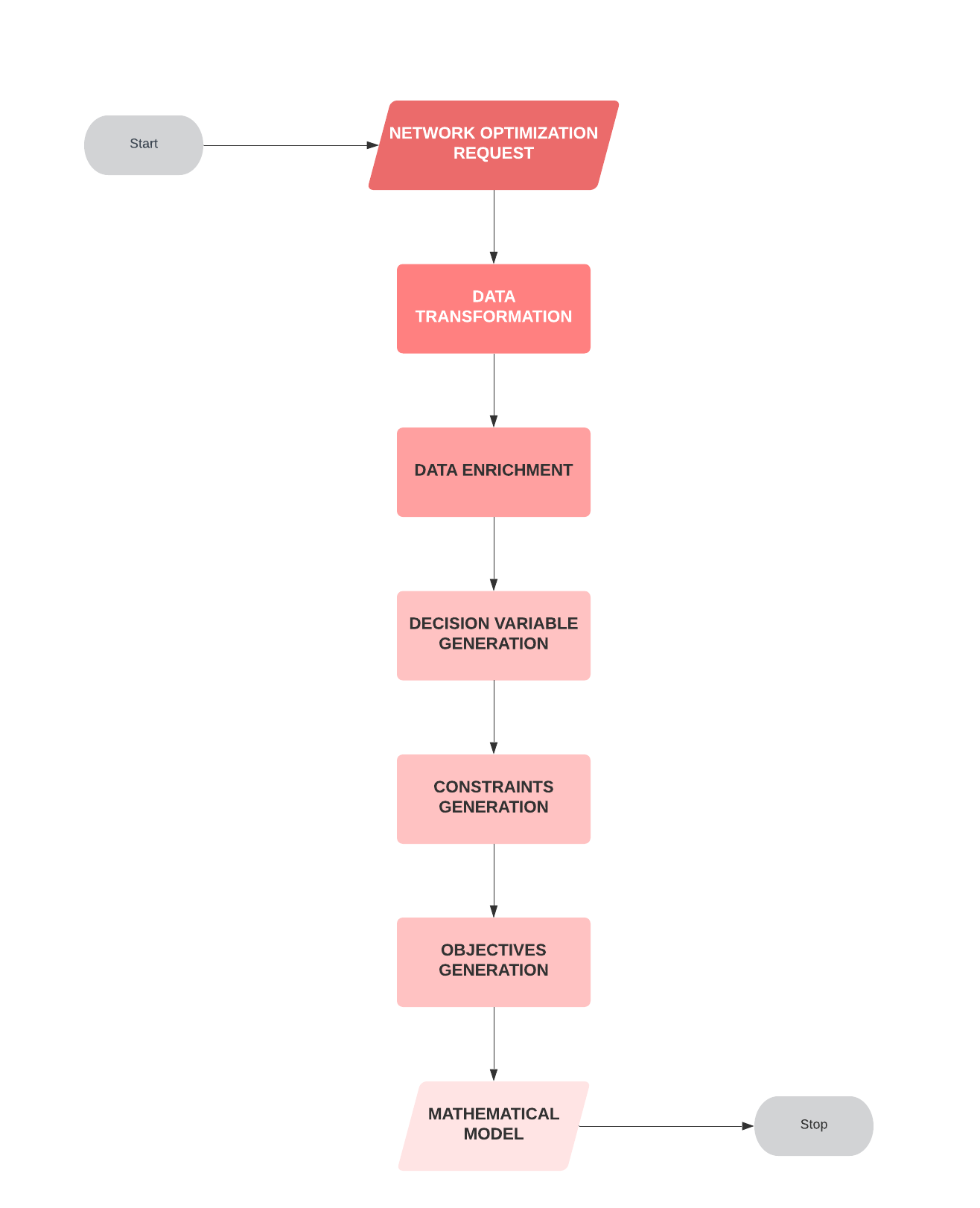
The first step in our network optimization pipeline is the transformation of the incoming request, which is then converted into decision variables. Enriching of the data and the variables follow. Additional constraints bring an added amount of complexity to the model and the codebase.
Furthermore, each stage needs to be scalable and fault-tolerant.
The construction of a mathematical model at the end of modeling is further processed to determine the optimal solution that requires parsing to a human-readable solution. Each stage in the workflow needs to be scalable and fault-tolerant.
These complexities encouraged us to design our codebase while keeping maintainability as one of the key metrics. Unfortunately, the maintainability of a traditional, imperative style codebase is questionable.
We know because we tried.
Even after ignoring the complexities of the above workflow, creating and maintaining a data science project requires efforts that are not exactly pertinent to improving the model. Even for a small project, writing the abstractions that future developers would need takes a significant amount of time. A key metric when creating such projects is maintainability since the person extending the codebase is not the one that developed it more often than not.
The idea is to extract the task execution pipeline to a separate module, so the focus is on model development and prototyping.
The motivation was to create a workflow management system that
- reduces boilerplate code
- reduces friction experienced while prototyping
- increases the speed of prototyping
- drastically increases maintainability
Objective:
Externalizing Neo helps us to draw strict boundaries of responsibilities and take advantage of the Python ecosystem. Along with serving as the modeler for NodeIQ, it also has the added responsibility to provide a playground for prototyping modifications to the modeler.
The workflow represented above is analogous to an assembly line, but with an imperative implementation, the intrinsic modularity of the logic is lost, unless continuous and significant attempts are made to keep the codebase sane.
Instead, each component should be isolated and be responsible for only one thing. The execution of a component should be independent of the other. This paradigm is commonly known as the single responsibility principle. Enter the pipeline design pattern!
You can find a beautiful explanation of the pipeline design pattern here.
From the above link,
This pattern is used for algorithms in which data flows through a sequence of tasks or stages from the link above. It represents a “pipelined” form of concurrency, as used, for example, in a pipelined processor.
Implementing the pipeline pattern requires us to structure the program as a directed graph of operations, a standard paradigm for expressing data processing and machine learning workflows.
Current pipeline management libraries are –
- Extremely opinionated and GUI-driven
- Designed specifically for machine learning problems
- Intrusive to the architecture; require resource allocation and separate deployment
We built a
- dumb
- developer-friendly
- simple pipeline abstraction module
- for managing workflows simulating a directed acyclic graph (DAG)
Before we start, I would like to show you what we achieved. But, first, take a moment to have a look at the workflow we had visualized above.
Following is the implementation of the workflow using the pipeline abstraction module.
Design:
Traditionally, a program is modeled as a series of operations happening in a specific order which forms the basis of the style of imperative programming we see today. This requires the developer to define the control flow programmatically. Maintaining branches of code and reusability of components becomes an overhead.
This is where dataflow programming comes into the picture. Instead of concerning ourselves with the execution flow, we think of the program in terms of the movement of data through a series of handlers with an explicit incoming and outgoing contract.
Each program is modeled as a directed set of operations where a developer defines the pipeline and its component steps. The data flowing through each node represents the state of the node, which we call the context.
In the following piece of code, we create a pipeline with two simple tasks. The first passes the input to an identity function, and the second squares each number of the input. The handlers are specified in-place functionally decoupling the control flow and the execution logic.
The complexity of any code can fractionally be determined by the friction experienced in writing a unit test for it. Following is the unit test for the above pipeline, demonstrating how one can trigger a pipeline.
That really is it. Once a pipeline has been created, it is straightforward to get it operational, and maintaining it has no friction due to the enhanced visibility of operations and handlers.
But this is not even the big reveal. How are the steps processed, you ask?
We promised you a line of code, and that is what you shall receive, even at the cost of being anti-climactic. Following is the processing code from the base data pipeline module.
The core orchestrator is the reduce method from functools where each step processes the context, and the first argument defines the handle for the method. This implements a linear workflow with a ridiculous amount of simplicity.
Philosophy:
To achieve the objectives such as enhanced maintainability and speed of prototyping, the library follows the governing principles listed below –
1. The channel should be unaware of the execution and scheduling logic
As seen in the snippets of code, the handlers for the actual execution are decoupled from the channel, which effectively works as a black box. This helps us achieve separation of concern. In addition, the logic regarding scheduling and condition execution also resides with the consumer rather than the channel.
2. Rely on code rather than voodoo
Machine learning and data science projects are ridden with scope creeps and varying requirements. The implementation should not add overhead to development. Various libraries commit this sin by having complex instrumentations and implementation via domain-specific languages or using configurations.
We use code. It is the most scalable form of implementation in the face of dynamic requirements and complex use cases. The following is a data-enriching pipeline from Neo, which has some of our most complicated flows.
3. Greater visibility leads to greater maintainability
This is a no-brainer. Maintainability is inversely proportional to the amount and complexity of code. The explicit description is an intentional step to provide a summary of the operation. The less code you write, the fewer bugs there are, and the lesser effort it requires to maintain a project.
The chain parameter can add branches to the control flow to explicitly separate concerns and segregate flows. For example, the pipeline we created above to square numbers is being reused below to raise the numbers by 4. Do have a moment and think what that would resemble.
4. Enhance extensibility via inversion of control
The base pipeline module implements the invariant parts of the architecture and provides hooks for implementing varying behavior as per the requirement. Hooks also provide a mechanism to monitor the pipeline and add customized logging to the application.
Summary:
This post briefly (hopefully!) describes the design of a pipeline abstraction module and the simplistic code behind the orchestration using the common reduce method.
Approaching a complex data science problem required us to re-think the way we traditionally write codebases. We discussed implementing the pipeline design pattern to increase the maintainability of complicated pieces of code and decrease the friction experienced while prototyping.
We are looking forward to hearing your feedback and possibly open source the module.
References:
- Pipeline design pattern #1
- Pipeline design pattern #2
- Single responsibility principle
- Collection pipeline
Inspirations:
First Published Source: How we wrote a pipeline abstraction module with one line of code

E-Commerce
Supermarkets in the Age of E-commerce
Jun 9, 2021
Times are a-changin’. To be fair, they have been changing ever since the boom of E-commerce. It is the pandemic that really shook things up though, and now that we’re more than a year into it, the face of retail looks completely different. As more and more customers hop online to make purchases, store isles […]
Read more
Featured
The Art of Problem-Solving: Shantanu Bhattacharya’s Journey from DNA to Data Science
Jun 14, 2021
There are some people who love what they do and there are others who love their work so much they decide to name their pet project after their daughter. Locus’s Chief Data Scientist, Shantanu Bhattacharyya belongs to the latter. But to call Shantanu a mere data scientist does not do justice to his extraordinary person […]
Read moreMOST POPULAR
EDITOR’S PICKS
SUBSCRIBE TO OUR NEWSLETTER
Stay up to date with the latest marketing, sales, and service tips and news
How we wrote a pipeline abstraction module with one line of code